In OOP/OOD, whenever we have a class (let’s call it the consumer) that uses a functionality provided by another class (let’s call this the provider), we have what is called a dependency. The consumer class needs a reference to the provider class in order to be able to access its functionalities. The easiest and most intuitive way to achieve this, is for the consumer to create an instance of the provider class calling one of the constructors of the provider (i.e. to “new” the provider).
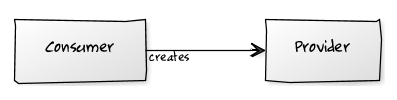
Direct Reference
This creates a tight coupling between the consumer and the provider. Changes to the provider class might require changes to the consumer class as well.
In the introduction of the best-selling book Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1995) – often referred to as the Gang of Four (GoF) book – the first principle that is mentioned is: “Program to an interface, not an implementation.” Erich Gamma, one of the author, describes this principle:
Once you depend on interfaces only, you’re decoupled from the implementation. That means the implementation can vary, and that’s a healthy dependency relationship. For example, for testing purposes you can replace a heavy database implementation with a lighter-weight mock implementation. […] So this approach gives you flexibility, but it also separates the really valuable part, the design, from the implementation, which allows clients to be decoupled from the implementation.
Translating this into UML, ideally we should get to the solution defined as a plugin by Martin Fowler in Patterns of Enterprise Application Architecture (P of EAA):
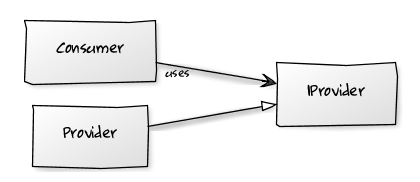
Program to an interface, not an implementation
This is actually only an ideal solution since the consumer class somehow needs to have a reference to an instance of the provider class and cannot directly instantiate the IProvider interface. A common solution is to introduce a factory in the mix, as show in the following UML diagram. The consumer calls the factory asking it to produce a concrete instance of the Provider class that implements the IProvider interface (the dotted line in the figure shows that, this way, the Consumer class gets a reference to the concrete Provider object).
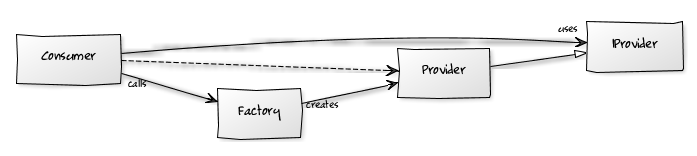
Using Abstraction
This eliminates the tight coupling between the consumer and the provider, but introduces coupling between the consumer and the factory, therefore it is still not an ideal solution.
The generally accepted solution to this problem is to use Inversion of Control (IoC), in which object coupling is bound at run time by an assembler object.
Two common techniques used to achieve this are:
- Service Locator Pattern
- Dependency Injection
Service Locator Pattern
Let’s begin by diving into a code snippet that shows how to implement the service locator pattern:
public class Consumer
{
private readonly IProvider _provider;
public Consumer()
{
_provider = IoCContainer.Get<IProvider>();
}
}
Using the service locator pattern is easy. A developer just needs to ask the IoC container for a specific service class. The IoC container looks to see if the request class has been configured and based on the lifetime management rules for the class it will either create a new instance or return a previously created instance to the requester. The major drawback to using this pattern is your code needs to direct access to the IoC container, which could introduce a tight coupling between your code and the API of the IoC container.
Dependency Injection
There are many ways in which an object can get a reference to an external module at run time. The two most commonly used are:
- Constructor Injection, in which the dependencies are provided through the class constructor.
public class Consumer
{
private readonly IProvider _provider;
public Consumer(IProvider provider)
{
_provider = provider;
}
}
- Setter Injection, in which the dependent module exposes a setter method that the framework uses to inject the dependency.
public class Consumer
{
private IProvider _provider
public IProvider Provider {
get { return _provider; }
set
{
if (value == null) throw new ArgumentNullException("value");
_provider = value;
}
}
public Consumer()
{
// code using Provider
}
}
* * *
Ok, let’s stop here for a second. We mentioned above the Service Locator Pattern. Mark Seemann, author of the book Dependency Injection in .NET, also wrote an interesting blog post in which he declares that the Service Locator is an anti-pattern and should be absolutely avoided. In his words, the problem is that
the Service Locator hides the dependency from a class, causing run-time errors instead of compile-time errors.
Look again at the tiny example of Service Locator few paragraphs above, and imagine that the Consumer class is something that we didn’t code ourselves and that we got from a third party in a DLL assembly, without the source code. As soon as we look at the constructor, all we can see from the outside is that the class has a constructor with no parameters. When we try to call it, though, we get an exception at run-time, because we have not properly configured the IoCContainer before calling the constructor of the Consumer class.
* * *
After having more or less digested all the above, one question I have is: “What is the difference between using the Service Locator anti-pattern and using the Castle Windsor container?” (click the question if you would like to try to help me out)
And when I have a question like that, the first place I go to find help is StackOverflow. Over there, while searching for an answer, I stumbled into an interesting and very controversial answer by Joel Spolsky, co-founder and CEO of Stack Exchange, to a similar question (note: bold in the following quote is mine):
IoC containers take a simple, elegant, and useful concept, and make it something you have to study for two days with a 200-page manual. I personally am perplexed at how the IoC community took a beautiful, elegant article by Martin Fowler and turned it into a bunch of complex frameworks typically with 200-300 page manuals.
I try not to be judgemental (HAHA!), but I think that people who use IoC containers are (A) very smart and (B) lacking in empathy for people who aren’t as smart as they are. Everything makes perfect sense to them, so they have trouble understanding that many ordinary programmers will find the concepts confusing. It’s the curse of knowledge. The people who understand IoC containers have trouble believing that there are people who don’t understand it.
The most valuable benefit of using an IoC container is that you can have a configuration switch in one place which lets you change between, say, test mode and production mode. For example, suppose you have two versions of your database access classes… one version which logged aggressively and did a lot of validation, which you used during development, and another version without logging or validation that was screamingly fast for production. It is nice to be able to switch between them in one place. On the other hand, this is a fairly trivial problem easily handled in a simpler way without the complexity of IoC containers.
I believe that if you use IoC containers, your code becomes, frankly, a lot harder to read. The number of places you have to look at to figure out what the code is trying to do goes up by at least one. And somewhere in heaven an angel cries out.
And that, at least for me, is a clear point against IoC containers. I mean, come on, the fact itself that this answer is the most controversial answer on StackExchange shows that I am certainly not the only one out there that doesn’t get this… at least not yet :)
On the other hand, when I take a look at the following example, I start to see where IoC containers could be helpful:
IoC Containers are also good for loading deeply nested class dependencies. For example if you had the following code using Depedency Injection.
public void GetPresenter()
{
var presenter = new CustomerPresenter(new CustomerService(new CustomerRepository(new DB())));
}
class CustomerPresenter
{
private readonly ICustomerService service;
public CustomerPresenter(ICustomerService service)
{
this.service = service;
}
}
class CustomerService : ICustomerService
{
private readonly IRepository repository;
public CustomerService(IRepository repository)
{
this.repository = repository;
}
}
class CustomerRepository : IRepository;
{
private readonly DB db;
public CustomerRepository(DB db)
{
this.db = db;
}
}
class DB { }
If you had all of these dependencies loaded into and IoC container you could Resolve the CustomerService and the all the child dependencies will automatically get resolved.
For example:
public static IoC
{
private IUnityContainer _container;
static IoC()
{
InitializeIoC();
}
static void InitializeIoC()
{
_container = new UnityContainer();
_container.RegisterType<ICustomerService, CustomerService>();
_container.RegisterType<IRepository, CustomerRepository>();
}
static T Resolve()
{
return _container.Resolve();
}
}
public void GetPresenter()
{
var presenter = IoC.Resolve();
// presenter is loaded and all of its nested child dependencies
// are automatically injected
// -
// Also, note that only the Interfaces need to be registered
// the concrete types like DB and CustomerPresenter will automatically
// resolve.
}
* * *
As it often happens, my quest brought me back to another post by Mark Seemann, and so I finally decided to buy his book “Dependency Injection in .NET” – if not for anything else, just to show my appreciation.
Turned out to be a very good decision, mostly because Mark has the uncommon talent to explain complex software engineering concepts in a way that would make them more or less understandable even by a person who is not a software engineer.
Just to give you an example, in the very first chapter, Mark revisits the common analogy between software interfaces and the electrical socket-and-plug model, and pushes it to the limit using it to explain all the following principles and design patterns:
- tight coupled composition vs. loosely coupled composition – through the use of the use of abstracted interfaces, where the implementations can be changed and multiple implementations could be created and polymorphically substituted for each other – in other words, the Open/Closed Principle (the “O” in SOLID)
- the Liskov Substitution Principle (the “L” in SOLID), which states that “we should be able to replace one implementation of an interface with another without breaking either client or implementation“
- the Null Object design pattern – which states that, instead of using a null reference to convey absence of an object (for instance, a non-existent customer), one uses an object which implements the expected interface, but whose method body is empty. The advantage of this approach is that a Null Object is very predictable and has no side effects: it does nothing.
- the Single Responsibility Principle (the “S” in SOLID), which states that every class should have a single responsibility, and that responsibility should be entirely encapsulated by the class
- the Decorator design pattern, which allows to intercept one implementation with another implementation of the same interface. This pattern is designed so that multiple decorators can be stacked on top of each other, each time adding a new functionality to the overridden method(s).
- the Composite design pattern, which makes it easy to add or remove functionality by modifying the set of composed interface implementations
- the Adapter design pattern, which can be used to match two related, yet separate, interfaces to each other.
And that’s just in the first chapter.
In the next chapter, Mark takes a simple but realistic example of a standard three-layer application architecture, implementing it twice. The first time he uses a traditional approach, what you and I probably have used many times – well, I don’t really know about you, but I know I did. The second time he uses Dependency Injection (DI). In the end, the architecture is completely reversed, as the final dependency graphs of the two implementations clearly shows:
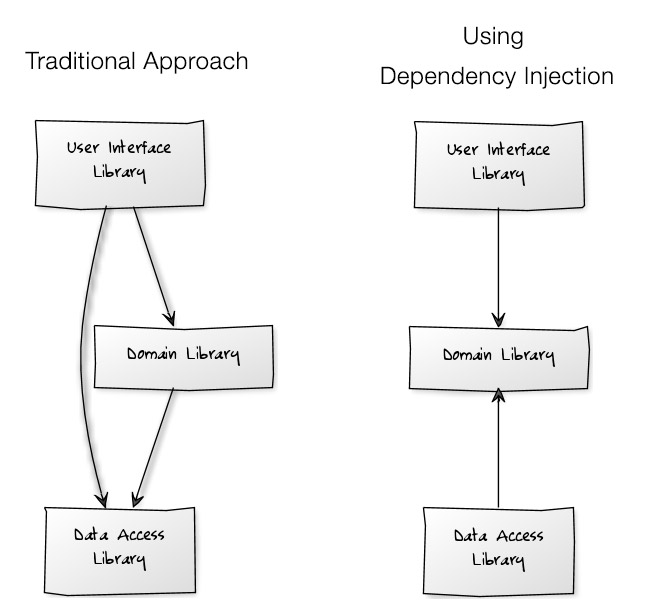
Following his reasoning behind every architectural choice was an eye opening experience. Nonetheless, while the exercise was incredibly useful, at this point I really didn’t need him to convince me that using DI is better. I already knew that.
Remember, at this point, I still haven’t found the answer to my question: “what is the difference between using the Service Locator anti-pattern and a DI Container?” In other words, I need to learn more about using DI containers, in particular where to use them and how to use them.
I finally found the answer I was looking for in Chapter 3 of Mark’s book, and it turns out that it really is not that difficult to deduce if only we go back to the way Dependency Injection works. We have seen it at the beginning of this (long) post, when I showed the two most common ways of injection, Constructor Injection and Setter Injection. When we use DI, we defer the decision about selecting the dependency to the assembler class, right? And if the assembler class also uses DI, and it should, in order to maintain a loosely coupled architecture, it will also defer that decision to its own assembler class. And so on… all the way to the Composition Root. Mark says:
The longer you defer the decision on how to connect classes together, the more you keep your options open. Thus, the Composition Root should be placed as close to the application’s entry point as possible. […]
You shouldn’t attempt to compose classes in any of the modules because that approach limits your options. All classes in application modules should use Constructor Injection and leave it up to the Composition Root to compose the application’s object graph. Any DI Container in use should be limited to the Composition Root.
I think this is a good place where to close this long post. The quest continues, obviously, but I think I have shared enough information and resources to allow you to take it from here and continue on your own. I would love to hear your opinions and ideas in regards, so please leave those in the comments to this post.






