This is a crosspost from The Digitalian
At the end of last post I quoted the eye-opening comment that Graph Grandmaster Wes Freeman left on one of my questions on Stack Overflow. Following his advice I decided to change the way each of the queues in my application was handled, adding two extra nodes, the head and the tail.
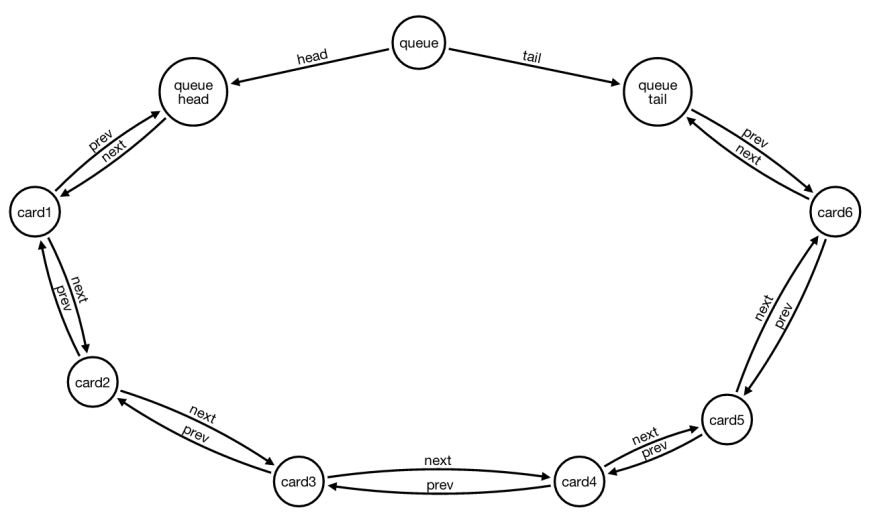
Inserting a New Card
Moving the concepts of head and tail from simple relationships to nodes allows to have a single case when inserting a new card. Even in the special case of an empty queue…
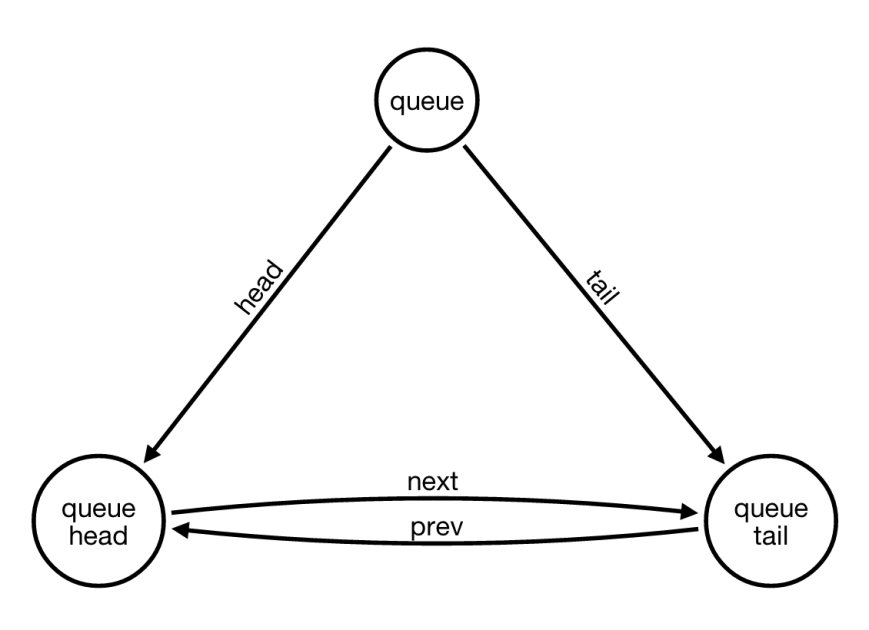
all we have to do to add a new card to the tail of the queue is:
- find the (previous) node connected by a [PREV_CARD] and a [NEXT_CARD] relationships to the (tail) node of the queue
- create a (newCard) node
- connect the (newCard) node to the (tail) node with both a [PREV_CARD] and a [NEXT_CARD] relationships
- connect the (newCard) node to the (previous) node with both a [PREV_CARD] and a [NEXT_CARD] relationships
- finally delete the original [PREV_CARD] and a [NEXT_CARD] relationships that connected the (previous) node to the (tail) node of the queue
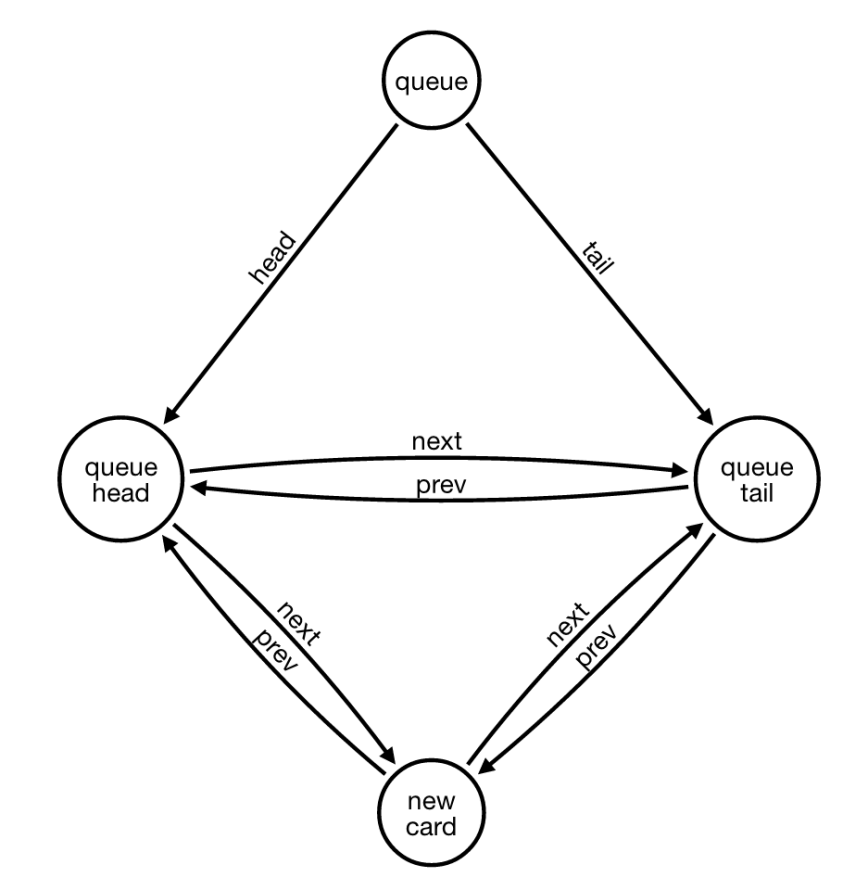
which translates into the following cypher query:
MATCH (theList:List)-[tlt:TAIL_CARD]->(tail)-[tp:PREV_CARD]->(previous)-[pt:NEXT_CARD]->(tail)
WHERE ID(theList)={{listId}}
WITH theList, tail, tp, pt, previous
CREATE (newCard:Card { title: "Card Title", description: "" })
CREATE (tail)-[:PREV_CARD]->(newCard)-[:NEXT_CARD]->(tail)
CREATE (newCard)-[:PREV_CARD]->(previous)-[:NEXT_CARD]->(newCard)
DELETE tp,pt
RETURN newCard
Archiving a Card
Now let’s reconsider the use case in which we want to archive a card. Let’s review the architecture:
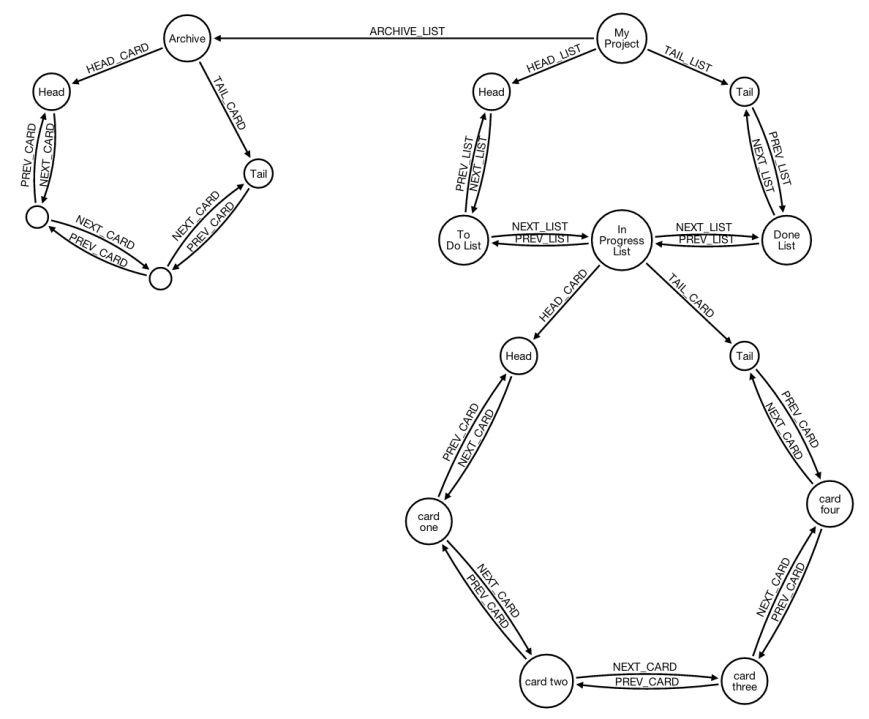
We have:
- each project has a queue of lists
- each project has an archive queue to store all archived cards
- each list has a queue of cards
In the previous queue architecture I had 4 different scenarios, depending in whether the card to be archived was the head, the tail, or a card in between or if it was the last card left in the quee.
Now, with the introduction of the head and tail nodes, there is only one scenario, because the head and the tail node are there to stay, even in the case in which the queue is empty:
- we need to find the (previous) and the (next) nodes, immediately before and after (theCard) node, which is the node that we want to archive
- then, we need to connect (previous) and (next) with both a [NEXT_CARD] and a [PREV_CARD] relationship
- then, we need to delete all the relationships that were connecting (theCard) to the (previous) and (next) nodes
The resulting cypher query can be subdivided in three distinct parts. The first part is in charge of finding (theArchive) node, given the ID of (theCard) node:
MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD]-(l:List)<-[:NEXT_LIST]-(h)(theArchive:Archive)
WHERE ID(theCard)={{cardId}}
Next, we execute the logic that I described few lines earlier:
WITH theCard, theArchive
MATCH (previous)-[ptc:NEXT_CARD]->(theCard)-[tcn:NEXT_CARD]->(next)-[ntc:PREV_CARD]->(theCard)-[tcp:PREV_CARD]->(previous)
WITH theCard, theArchive, previous, next, ptc, tcn, ntc, tcp
CREATE (previous)-[:NEXT_CARD]->(next)-[:PREV_CARD]->(previous)
DELETE ptc, tcn, ntc, tcp
Finally, we insert (theCard) at the tail of the archive queue:
WITH theCard, theArchive
MATCH (theArchive)-[tat:TAIL_CARD]->(archiveTail)-[tp:PREV_CARD]->(archivePrevious)-[pt:NEXT_CARD]->(archiveTail)
WITH theCard, theArchive, archiveTail, tp, pt, archivePrevious
CREATE (archiveTail)-[:PREV_CARD]->(theCard)-[:NEXT_CARD]->(archiveTail)
CREATE (theCard)-[:PREV_CARD]->(archivePrevious)-[:NEXT_CARD]->(theCard)
DELETE tp,pt
RETURN theCard
Performance
I am very satisfied with how much simpler the new queries are, both to write and to understand, when compared to the older one discussed in the previous post of this series. At this point Wes suggested to run some performance tests. The results can be found below. Not much of a difference from a performance point of view – especially because this was an end-to-end performance test, calling N times the server, executing one insertion/archival at a time.
I ran each test three times, with the individual times in columns TIME 1, TIME 2 and TIME 3.
Using the New Architecture
TEST #1: INSERT (n) CARDS (in the same list)
| # CARDS | TIME 1 (ms) | TIME 2 (ms) | TIME 3 (ms) |
| 10 | 77 | 56 | 58 |
| 100 | 552 | 534 | 526 |
| 1000 | 5133 | 4978 | 4903 |
| 10000 | 51342 | 51454 | 54709 |
TEST #2: ARCHIVE (n) CARDS (from the same list)
| # CARDS | TIME 1 (ms) | TIME 2 (ms) | TIME 3 (ms) |
| 10 | 54 | 56 | 55 |
| 100 | 509 | 402 | 377 |
| 1000 | 3395 | 3508 | 2903 |
| 10000 | 27675 | 23381 | 22312 |
Using the Old Queries
TEST #3: INSERT (n) CARDS (in the same list)
| # CARDS | TIME 1 (ms) | TIME 2 (ms) | TIME 3 (ms) |
| 10 | 116 | 118 | 111 |
| 100 | 1019 | 996 | 899 |
| 1000 | 7673 | 6262 | 6200 |
| 10000 | 62680 | 55663 | 58081 |
TEST #4: ARCHIVE (n) CARDS (from the same list)
| # CARDS | TIME 1 (ms) | TIME 2 (ms) | TIME 3 (ms) |
| 10 | 148 | 133 | 124 |
| 100 | 954 | 784 | 676 |
| 1000 | 4958 | 3950 | 3539 |
| 10000 | 26921 | 23908 | 22942 |
Conclusions
I hope you find this post interesting as I found working through this exercise. I want to thank again Wes for his remote help (via Twitter and Stack Overflow) in this interesting (at least to me) experiment.
